Study
本文最后更新于:9 天前
2024.10.16
卷积神经网络CNN
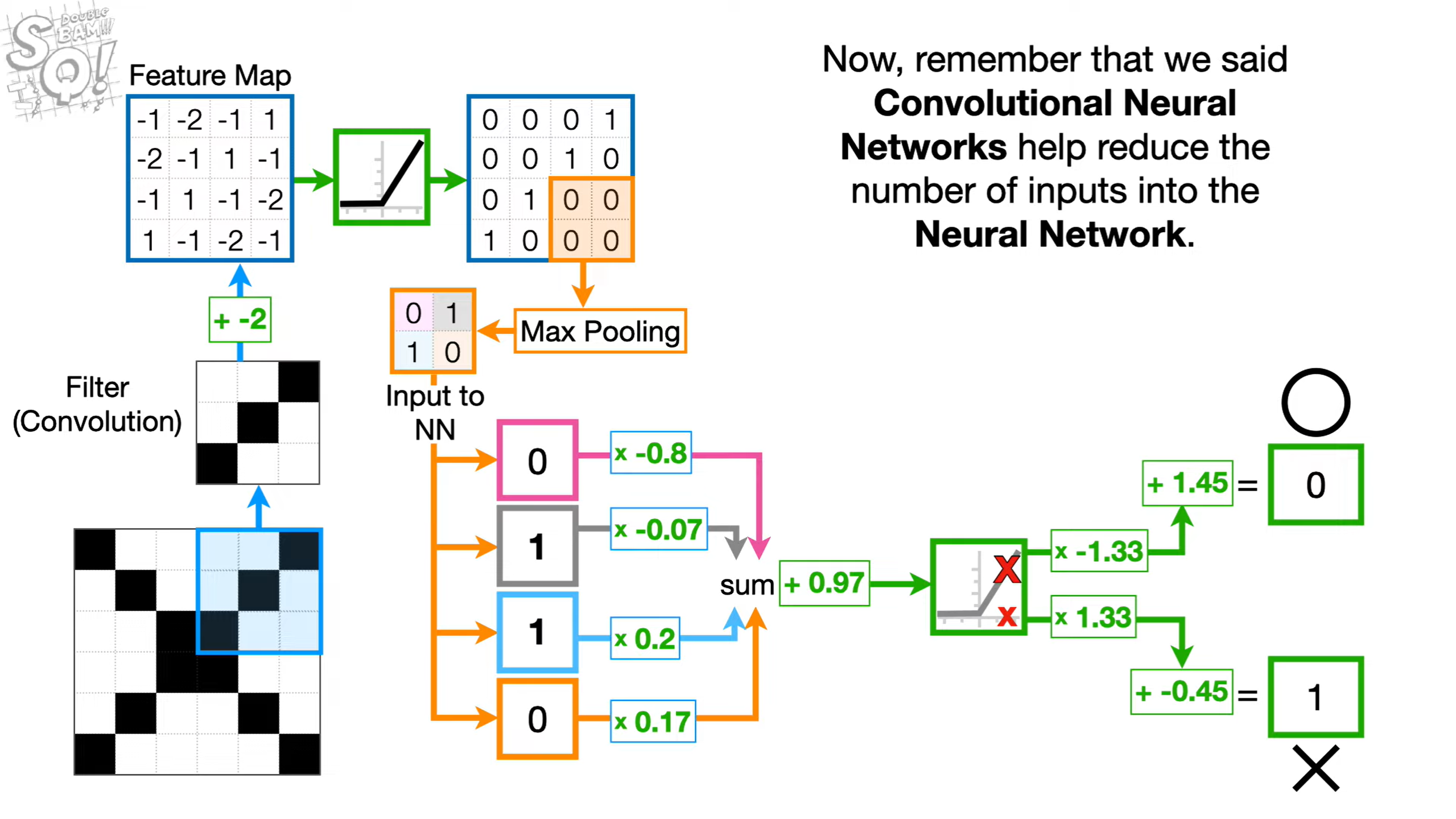
卷积神经网络的运行过程主要通过以下步骤:
- 输入层主要负责图像的输入。
- 再通过卷积层,对图像的特征进行提取;卷积层通过使用卷积核(Filter/Kernel)对数据进行卷积操作,再通过滑动操作对整个图像进行特征提取后生成相应的**特征图(Feature Map)**。
- 通过最大池化(Max Pooling)或平均池化(Avg Pooling),来进行降采样,在减少特征图尺寸的同时保留其显著特征。
- 池化后的特征图传入神经网络(Neural Network)中,由神经网络对图像内容进行预测。
循环神经网络 RNN
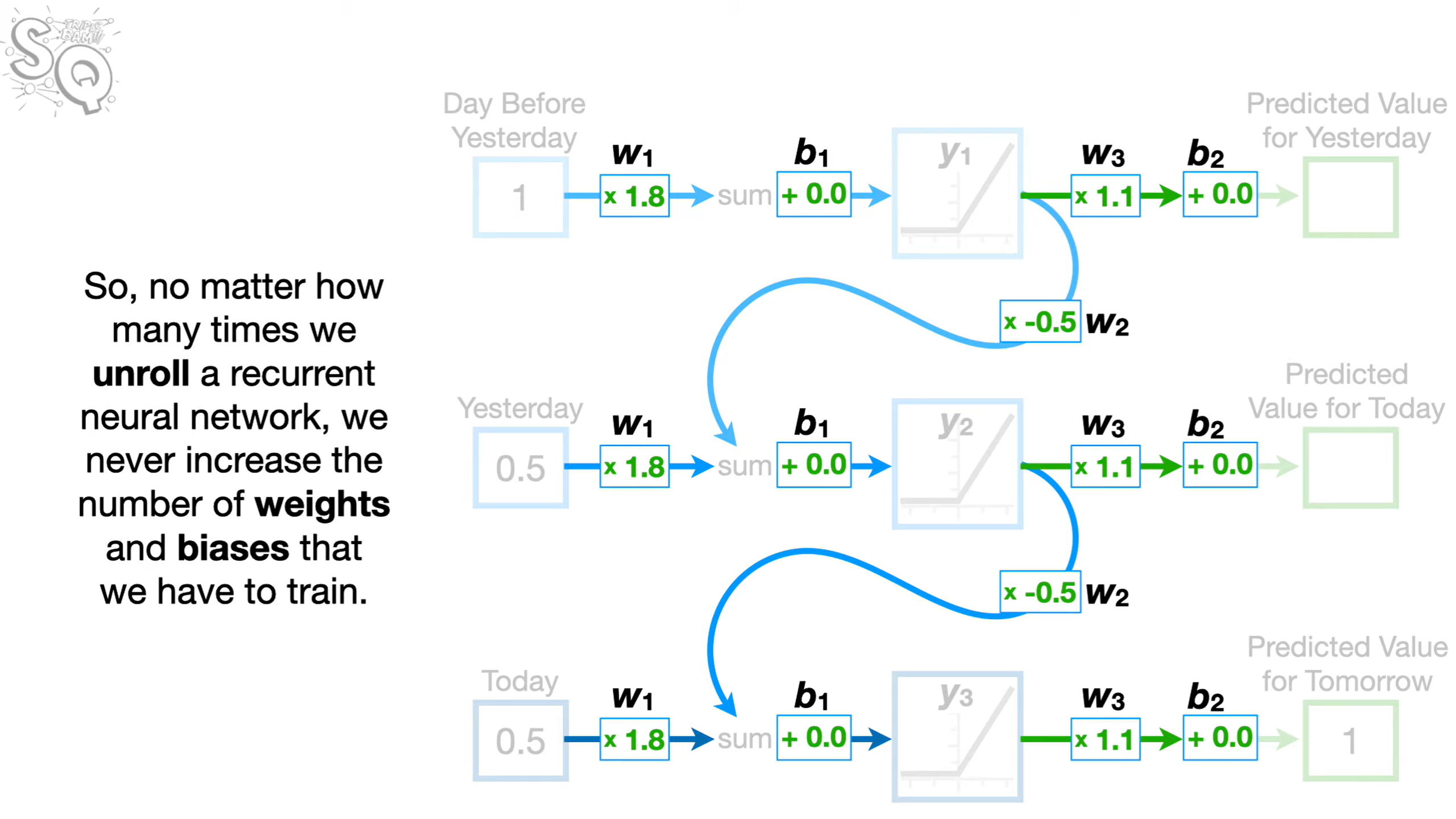
循环神经网络的主要特征是具备了处理时间序列或顺序数据依赖的能力;由于其的循环连接和展开,使得每一个输出都不仅仅依赖于当前的输入,还依赖于上一个时间步的隐藏状态。
但当需要处理的数据序列较长时,由于展开的特性,会出现梯度爆炸/消失问题。如上图,当存在50个前置数据时,经过多次与w2相乘,导致梯度会下降到2-50,也就是所谓的梯度消失问题;同理,当w2大于1时,则为梯度爆炸。
长短期记忆神经网络 LSTM
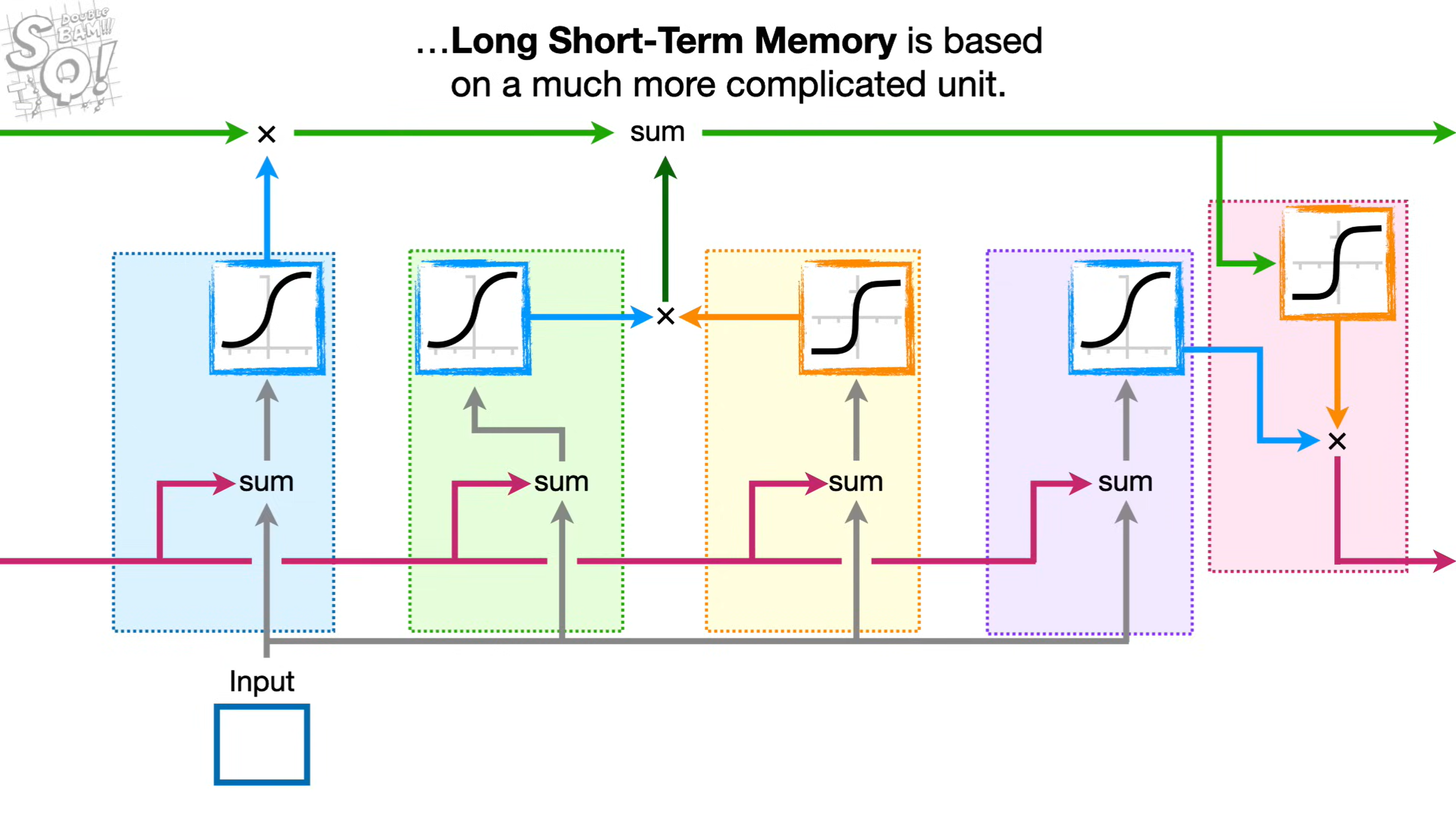
长短期记忆LSTM有效解决了RNN中的梯度爆炸/消失问题。框架图如上图。
- 最上方的绿色线条表示长期记忆L也称作细胞状态,用于保存先前输入的数据
- 蓝色部分为遗忘门,通过本次输入,再经过Sigmod函数生成相应的遗忘率,与长期记忆L相乘表示“记住”多少内容。
- 假设计算后为
97%,则本次L遗忘内容较少 - 假设计算后为
5%,则长期记忆就将遗忘大部分内容
- 假设计算后为
- 绿色和黄色部分为输入门,黄色部分计算潜在的长期记忆(Potential Long-Term Memory),用于生成L需要记住的内容;绿色部分用于计算潜在长期记忆需要记住多少(% Potential Memory To Remember)。相乘后添加到长期记忆L**中。
- 紫色和粉色部分为输出门,首先对输入和短期记忆进行计算,计算**短期记忆需要记住多少(% Potential Memory To Remember)**,再同上方的长期记忆进行运算,最终生成预测值。
Word Embedding and Word2Vec
为了将单词转换为相应的向量,以便于输入计算机进行处理,引入了Word2Vec方法。
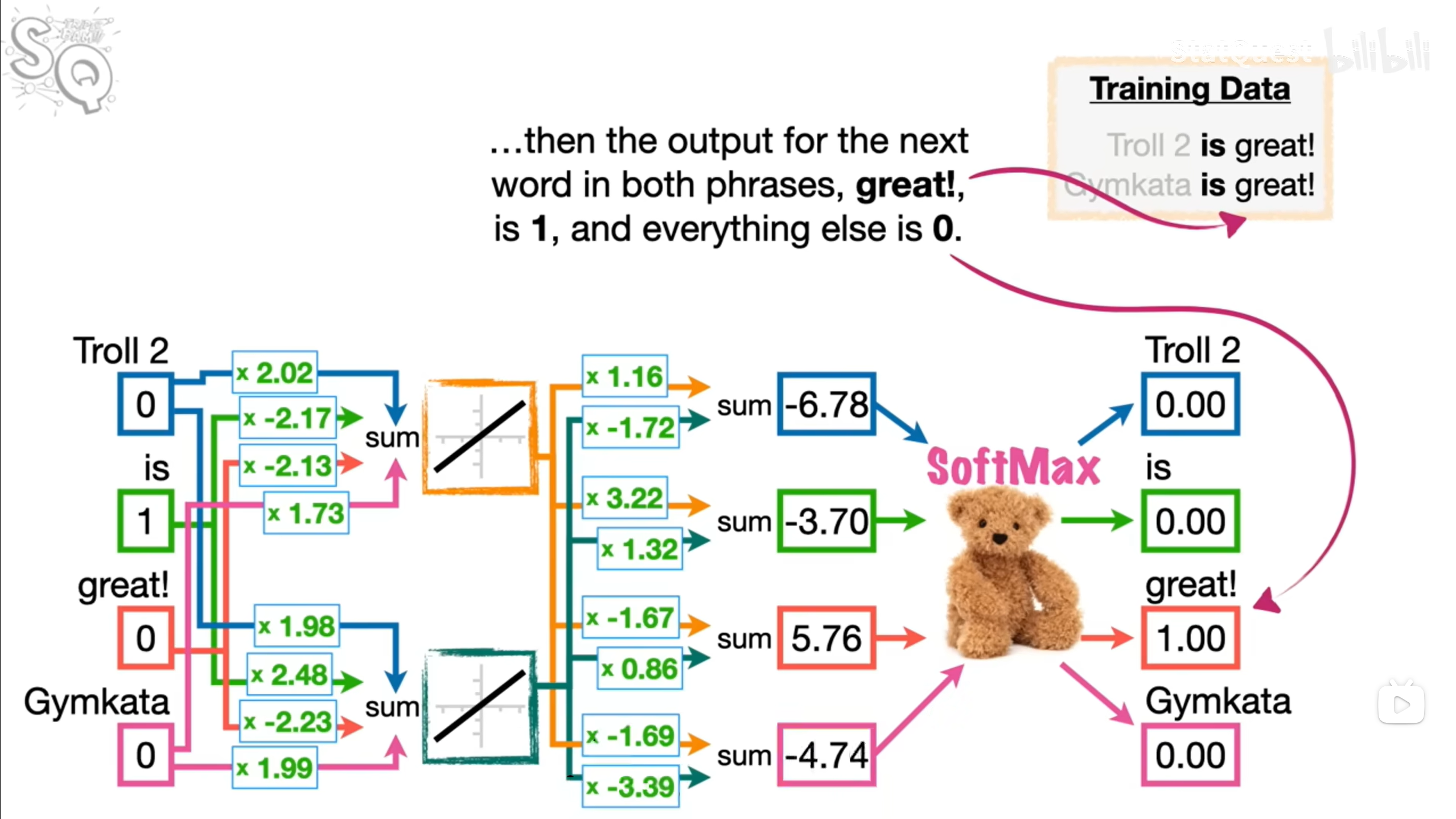
其本质上仍然是一个神经网络模型,初始状态的权重为随机,通过反向传播进行训练,最终得到的权重w即为所谓的Word Embedding。除了顺序预测之外,还有**连续词袋(Continuous Bag of Words),通过间隔的单词来预测中间的单词;或是跳跃词袋(Skip Gram)**,通过中间单词来主动预测两边的单词。
总的来说,Word2Vec就是将单词转换为计算机可理解的向量。
Word2Vec 通过训练模型,生成低维的、密集的向量表示,其中:
- 相似的单词(例如,”king” 和 “queen”)在向量空间中距离较近。
- 单词的语义关系可以通过向量的算术运算表示(如 “king” - “man” + “woman” ≈ “queen”)。
Seq2Seq
Seq2Seq的本质实际上是编码器-解码器。它通过将某一序列经过编码后(如Word2Vec)输入进编码器神经网络中进行处理;需要注意,这里的神经网络可以是RNN、LSTM或GRU,且会是多层,同层次共享相同的权重和偏移。再将产生的上下文向量(Context Vector)传递给解码器部分,由解码器输入再次进行解码,传入全连接层(也是一种神经网络),最终产生相应的预测输出传递给下一次的解码器的输入。
注意:训练过程中,解码器会使用训练的Token而不是全连接层的输出作为输入。
Attention
RNN的主要缺陷,是由于其使用单一路径来处理长期记忆和短期记忆,导致梯度爆炸/消失。LSTM会在输入大量数据时,或多或少的遗忘较长时间之前的记忆。由此提出了Attention机制,它的核心思想是对每一个输入,都有一条直接路径连接解码器,这样解码器每一步解码都可以直接访问输入值。
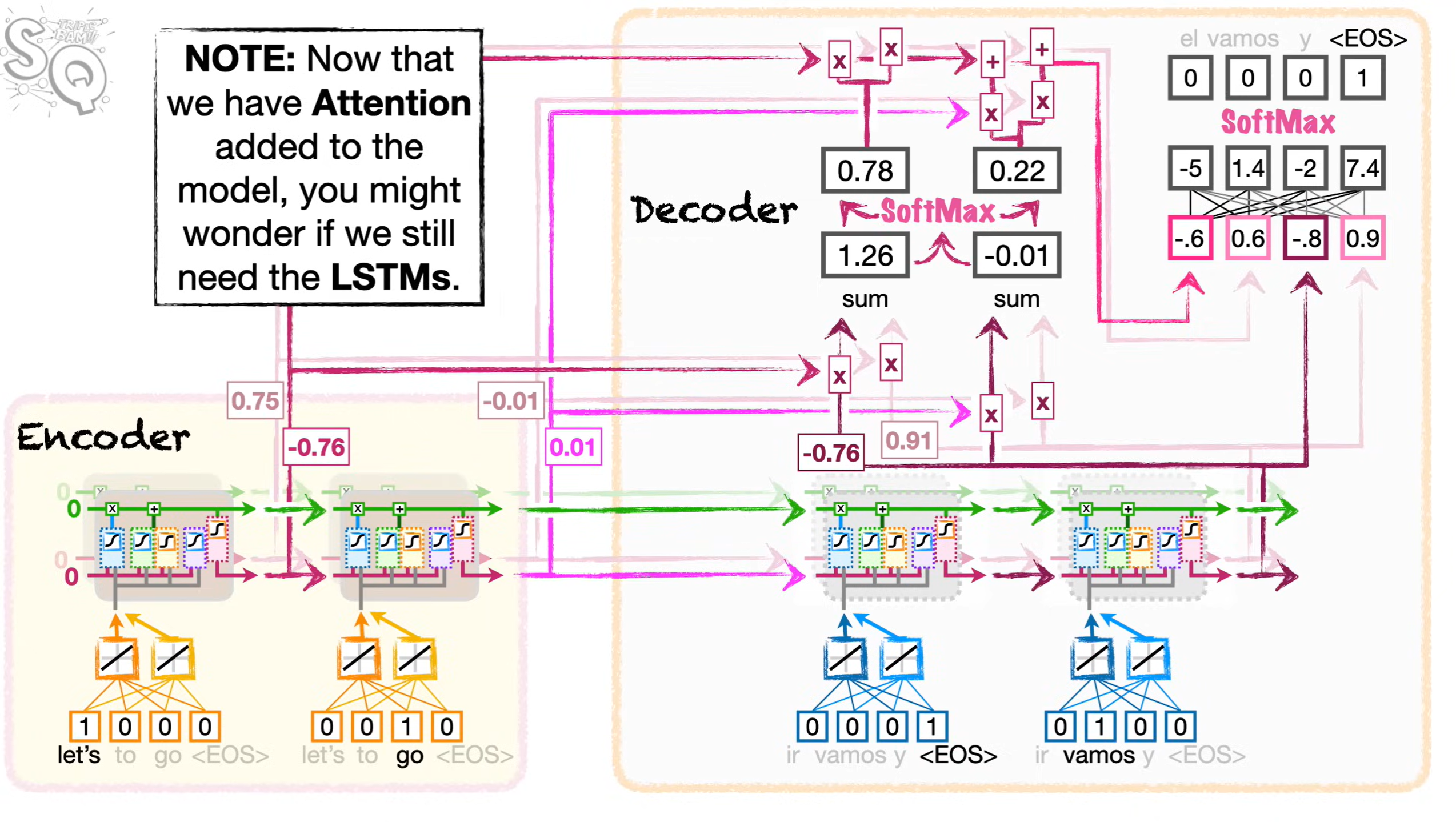
将Let's以及go同解码器的第一个输入<EOS>进行点积运算后,生成相应得相似度值,计算公式如下:
$$
Cosine Similarity = (\frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}})
$$
注意,公式的分母部分主要用于将输出的值缩放到(-1, 1)之间,使其比较时相对简单,在实际使用时可以仅使用分子部分**(点乘Dot Product)**进行比较。
将计算出的相似度值进行SoftMax运算后,得出的结果表示该相似度在解码时,我们使用该编码的单词的百分比。将加权后的值相加(即Let's和go对于<EOS>的相似度的值)后得出的值为二者对<EOS>的相似度,也就是<EOS>的注意力值。
再将Let's和go的相似度值,同<EOS>的编码值一同输入进全连接层,运算后使用SoftMax决定下一个输出的单词;然后将产生的输出作为解码器的新输入,重复上述过程,最终得到最后的输出<EOS>